
Automating Threat Intelligence series
4 Maggio 2025












Vulnerability Management

Vulnerability Management è già stato detto molto, e io stesso ne ho già parlato più volte qui, ma, indubbiamente, la gestione delle vulnerabilità è ancora un grosso problema nella maggior parte delle aziende.
Le attività offensive che svolgiamo rivelano come, a fronte di un esito positivo, l’attack path sia possibile grazie a vulnerabilità software o logiche. E quasi sempre le vulnerabilità erano note al reparto IT ma, per qualche motivo, non era stato possibile fare alcuna mitigazione.
In altre parole l’azione offensiva ha avuto successo grazie a vulnerabilità ampiamente conosciute.
E questa non è un caso raro.
Cos’è una vulnerabilità
Nel senso più comune (e tecnico) del termine, vulnerabilità è un errore software che permette di compromettere le proprietà di confidenzialità, integrità, e/o disponibilità. Tuttavia questa è una categoria ben precisa. Se ampliamo il significato, il termine vulnerabilità si può applicare a:
- Processi
- Persone
- Configurazioni
Vulnerabilità di processo
Una vulnerabilità di processo si ha, ad esempio, quando le informazioni cartacee non seguono una via che permetta di rispettare la confidenzialità e rischiano di essere viste da persone che non hanno titolo di vederle. In un caso reale mi è capitato di intercettare lo scatolone delle buste paga dell’azienda che in quel momento si trovava incustodito. Nel caso specifico la persona si stava comportando come da procedura la quale non teneva conto di questo tipo di rischio.
Vulnerabilità psicologica
Una vulnerabilità psicologica si ha, ad esempio, quando, grazie a tecniche di ingegneria sociale, l’attacker riesce ad ottenere informazioni sensibili. Phishing, tailgating, e piggybacking sono tecniche tipiche che sfruttano debolezze psicologiche.
Vulnerabilità di configurazione
Una vulnerabilità di configurazione (detta anche logica) si ha, ad esempio, quando una condivisione di rete permette l’accesso a persone non autenticate. In molti casi questo tipo di vulnerabilità esiste per dimenticanza, ma in altri casi esiste perché chi ha fatto la configurazione non possedeva le conoscenze adeguate per farlo in sicurezza.
Dovremmo menzionare le vulnerabilità che impattano il mondo fisico, come serrature, porte, gate… ma rischieremmo di focalizzarci troppo sul tecnico e preferisco invece restare ad un livello più generale, applicabile facilmente ai diversi contesti.
Gestire le vulnerabilità
In moltissimi casi quando parlo di vulnerability management le persone associano l’idea di patching. Gestire una vulnerabilità non significa eliminarla mediante una patch software. Gestire una vulnerabilità significa valutarne il rischio e mitigarlo. La mitigazione può avvenire mediante:
- patching o correzione della configurazione
- spegnimento del sistema vulnerabile
- training (riferito alle persone)
- aggiunta di ulteriori controlli di sicurezza
- …
All’estremo il rischio può essere trasferito mediante assicurazioni (che a loro volta effettueranno una valutazione del rischio escludendo, tipicamente, le aziende più fragili).
Valutare una vulnerabilità
Non tutte le vulnerabilità sono uguali. Anzi ciascuna vulnerabilità ha caratteristiche uniche per tipologia, impatto, sfruttabilità, mitigabilità. Non possiamo quindi limitarci al classico report, ma dobbiamo integrarlo con informazioni pubbliche, che variano temporalmente, e informazioni specifiche per la nostra organizzazione.
In altre parole, dobbiamo approcciare il problema con una mentalità risk-based.
Occorre sottolineare un fatto: il rischio associato a ciascuna vulnerabilità varia nel tempo: tipicamente (ma non sempre) una vulnerabilità viene scoperta, dopo un certo tempo viene sfruttata e diventa quindi pericolosa. Inoltre solo nel 2024 abbiamo visto diversi esempi di patch che si sono rivelate insufficienti a risolvere il problema. In questo senso dobbiamo tenere presente che ciascuna vulnerabilità deve essere monitorata nel tempo.
Possiamo ipotizzare di associare a ciascuna vulnerabilità il rischio che essa venga sfruttata in modo malevolo. Nella nostra formula dobbiamo sicuramente tenere conto di:
- se la vulnerabilità è, nella pratica, sfruttabile;
- se esistono exploit pubblici;
- se ci sono evidenze, world-wide, che essa è sfruttata da threat actor;
- su quali asset questa vulnerabilità è presente e in particolare l’impatto sui dati contenuti in questi asset;
- la possibilità di lateral movement, ossia la possibilità che la minaccia si diffonda da un asset compromesso agli asset adiacenti;
- eventuali misure di sicurezza esistenti atte a bloccare eventuali minacce sugli asset vulnerabili.
Possiamo semplificare riducendo l’elenco a tre fattori:
- probabilità che una vulnerabilità sia sfruttata considerando il contesto globale;
- impatto sull’organizzazione se questa vulnerabilità venisse sfruttata;
- mitigazione della minaccia grazie alle misure di sicurezza presenti.
CVSS Score ≠ rischio
Prima di parlare di come possiamo valutare una vulnerabilità, dobbiamo fare chiarezza su un mito che spesso trovo radicato nelle persone: il valore di CVSS non può essere la base del nostro processo di valutazione delle vulnerabilità.
La prima ragione è che una vulnerabilità potrebbe non avere una CVE associata. I motivi per cui questo succede sono diversi:
- non è detto che chi ha scoperto la vulnerabilità abbia la voglia e il tempo di farsi riconoscere una CVE;
- non è detto che la vulnerabilità sia software e che quindi sia possibile associare una CVE.
Il secondo motivo, come ci dice il sito del FIRST, è che il valore di CVSS è calcolato assumendo che ci siano tutti i prerequisiti che rendono la vulnerabilità sfruttabile:
if a specific configuration is required for an attack to succeed, the vulnerable system should be assessed assuming it is in that configuration.
Il CVSS misura la criticità di una vulnerabilità, non il rischio associato ad essa. Con le dovute cautele può essere usato per calcolare il rischio, ma occorre riempire il vuoto per le vulnerabilità che non hanno una CVE associata.
Valutare nella pratica una vulnerabilità
Il mio approccio mi porta a suggerire azioni pratiche e sostenibili alle aziende affinché possano portare un miglioramento veloce ed efficace alla sicurezza aziendale. A costo di semplificare eccessivamente la teoria, il mio focus è sempre sull’obiettivo.
Abbiamo visto che non possiamo usare CVSS, sia perché è un’indicazione che deve essere contestualizzata, sia perché non tutte le vulnerabilità hanno una CVE associata.
Molti strumenti per rilevare vulnerabilità ipotizzano, per semplicità, un fattore di rischio. Questo semplifica molto l’uso dello strumento ma il dato deve essere completato con le informazioni di contesto.
Nella pratica, il sistema più semplice (ma scorretto come vedremo in seguito) consiste nell’uso di tool di vulnerability scanning che identificano le vulnerabilità latenti, associando un fattore di rischio a ciascuna vulnerabilità.
È, purtroppo, piuttosto comune che nelle aziende attività di vulnerability scanning rilevino migliaia o decine di migliaia di vulnerabilità più o meno critiche. È altrettanto comune leggere un senso di sconforto nei manager che visionano questo tipo di report perché la vetta da raggiungere, vista da questa prospettiva, sembra impossibile.
Il problema è che in qualsiasi organizzazione esistono delle attività che sono prioritarie rispetto a qualsiasi cosa. In altre parole le vulnerabilità continueranno ad aumentare perché:
- alcuni sistemi non si possono spegnere;
- alcuni sistemi sono intoccabili;
- alcuni sistemi sono critici ma non esiste più supporto;
- nessuno vuole trovarsi nella situazione di installare una patch fallata e compromettere un servizio aziendale critico.
Ho già parlato di assume breach design, e provo a riportare il concetto: qualsiasi sistema deve essere disegnato tenendo presente che prima o poi potrebbe essere compromesso. Nel caso specifico: se un’organizzazione ha un certo numero di sistemi intoccabili, essi devono essere posizionati in un’area ad alta sicurezza. Questa situazione si verifica sempre nel mondo ICS/OT e ho già affrontato il tema in un post specifico.
In questo senso la gestione delle vulnerabilità deve iniziare nella fase di design dove vengono considerate le misure di sicurezza per ridurre il rischio di compromissione. Ma possiamo lavorare anche a posteriori, con molta fatica, per ripensare l’architettura.
Il mio approccio, opportunamente semplificato (e incompleto), per valutare una vulnerabilità consiste nel:
- utilizzare il fattore di rischio suggerito dallo strumenti di vulnerability scanning;
- eventualmente correggere tale fattore se il contesto lo richiede;
- applicare un valore correttivo che riflette l’impatto sull’organizzazione;
- applicare un valore correttivo che riflette le misure di sicurezza implementate nell’organizzazione.
Nella pratica:
- il fattore di rischio viene raramente personalizzato;
- il fattore di rischio considera la vulnerabilità al netto di qualsiasi misura di sicurezza presente, ossia rappresenta un asset esposto pubblicamente;
- l’impatto sull’organizzazione è un fattore precalcolato per ciascuna zona di sicurezza (in questo senso ipotizzo che una compromissione possa espandersi liberamente all’interno della stessa zona);
- il valore correttivo è precalcolato per le misure di sicurezza presenti in azienda (firewall, IPS, EDR, SIEM…).
Ovviamente l’approccio è impreciso, incompleto e in parte errato (vediamo in seguito perché), tuttavia il contributo che porta alle organizzazioni è enorme:
- le migliaia di vulnerabilità vengono ora pesate in base alle misura di sicurezza presenti, ed è possibile definire delle priorità;
- vengono considerate le misure di sicurezza, il che permette di ragionare se spostare gli asset intoccabili in zone separate;
- viene considerato l’impatto di un attacco completo, non solo relativo all’asset vulnerabile;
- permette di definire le motivazioni in base alle quali è corretto che alcuni asset siano privi di aggiornamenti.
Questo approccio, denominato a volte come risk-based vulnerability assessment, sta trovando sempre più spazio. In particolare sto notando che il mondo della compliance e delle assicurazioni accettano di buon grado un approccio risk-based e lo valutano positivamente.
In altre parole è giustificato che esistano delle vulnerabilità critiche, a patto che esse siano gestite con un approccio risk-based.
Prevedere il futuro
In un approccio pragmatico, una vulnerabilità è tale se può essere sfruttata. Sono molte le vulnerabilità che richiedono condizioni così specifiche da rendere, di fatto impraticabile lo sfruttamento. Il valore di CVSS tiene conto della complessità dell'attacco, ma ne tiene conto con due sole possibilità: low e high.
FIRST ha definito un parametro che rappresenta la probabilità che una vulnerabilità sia sfruttata nei prossimi 30 giorni:
EPSS is a measure of exploitability. Specifically, EPSS is estimating the probability of observing any exploitation attempts against a vulnerability in the next 30 days.
Il valore di EPSS (Exploit Prediction Scoring System), variabile nel tempo, ci aiuta a definire lo SLA per mitigare ciascuna vulnerabilità che abbia una CVE associata.
Mitigare una vulnerabilità
Arrivati a questo punto dovremmo avere una lista di vulnerabilità con associato il rischio al netto delle misure di sicurezza (Inherent Risk) e un fattore di mitigazione che rappresenta le misure di sicurezza in atto (EDR, firewall, awareness…). La combinazione di questi due fattori ci permette di ottenere il rischio che una vulnerabilità venga sfruttata considerando le misure di sicurezza (Residual Risk).
Prima di ordinare questo elenco in ordine decrescente di rischio e cominciare a compilare il remediation plan, ci manca un ultimo fattore: la propensione al rischio (Risk Appetite). Questo fattore indica il rischio che la nostra Organizzazione ritiene accettabile. Una volta definito, tutte le vulnerabilità con Residual Risk al di sotto di questo fattore, vengono automaticamente ignorate. Se abbiamo qualche dubbio, significa che il nostro modello di rischio ha qualche errore.
Abbiamo quindi ottenuto un elenco di vulnerabilità reali, sfruttabili, per le quali il rischio non è considerato accettabile. Dobbiamo quindi definire le azioni per ridurre il rischio di ciascuna vulnerabilità.
Il rischio può essere:
- risolto, ad esempio aggiornando il software vulnerabile o spegnendolo;
- mitigato, inserendo una nuova misura di sicurezza (ad esempio spostando il sistema vulnerabile in una zona di sicurezza maggiore);
- trasferito, ad esempio tramite assicurazioni o terze parti.
Patching
Spesso possiamo risolvere una vulnerabilità installando un aggiornamento. In questi casi dobbiamo però chiederci quando questa azione deve essere fatta. Ho visto organizzazioni con politiche di patching mensile, nel migliore dei casi. Ma nei peggiori troviamo sistemi che vengono aggiornati una volta l’anno o anche meno.
Per prima cosa, ciascun sistema e applicativo, dovrebbe avere una finestra di manutenzione ben definita.
Per seconda cosa dobbiamo associare a categorie di rischio uno specifico SLA: più è alto il rischio, più veloce deve essere l’installazione degli aggiornamenti e di conseguenza le finestre di manutenzione devono essere previste in intervalli più stretti. Paradossalmente più il sistema è critico dal punto di vista aziendale, più spesso deve poter essere fermato per manutenzione.
Per questo motivo nelle organizzazioni si tende a fare quello che io chiamo “blind patching”, ossia patching che si focalizza non sul rischio, ma sui sistemi più semplici da aggiornare. E questa è l’esatta ragione che causa l’accumulo di centinaia o migliaia di vulnerabilità all’interno di tantissime aziende.
Occorre fare un’ulteriore considerazione sulle attività di patching. Spesso tali attività non hanno la giusta “dignità”. Le persone che si occupano di patching lo fanno a loro rischio e pericolo:
- se tutto va bene, non ne hanno alcun riconoscimento;
- se qualcosa va male, risultano essere la causa del disservizio e comunque è responsabilità loro ripristinare il servizio.
In questo clima le persone eviteranno di prendersi in carico le attività di patching, causando ulteriori ritardi. Se pensiamo quindi che il mancato patching sia un problema di risorse, ci troveremo ben presto a scoprire che il problema è che nessuno vuole premere il pulsante e la relativa responsabilità.
Dal punto di vista organizzativo è impensabile che esista un team trasversale responsabile degli aggiornamenti software. Ciascun sistema serve un’applicazione che è necessaria per il business. In questo senso applicazioni e sistemi hanno un responsabile assegnato che garantisce il servizio. Se vogliamo che il processo funzioni, non possiamo disaccoppiare la responsabilità applicativa e la responsabilità degli aggiornamenti.
L’ultima considerazione riguarda il tempo massimo per mitigare una vulnerabilità. Tale tempo dipende da condizioni che variano nel tempo (abbiamo già parlato di EPSS). Vale la pena però citare un report di Cloudflare:
CVEs exploited as fast as 22 minutes after proof-of-concept published

22 minuti sono un tempo impossibile per gestire queste vulnerabilità a mano. In 22 minuti probabilmente nemmeno ci si accorge della nuova vulnerabilità. Dobbiamo pensare ad un approccio diverso.
Mitigare il rischio
Abbiamo già detto che il patching è una delle possibilità per gestire le vulnerabilità software. Esistono però tantissimi casi dove il patching non può essere fatto. Le ragioni solitamente sono:
- l’applicazione non può essere fermata così frequentemente da permettere un patching continuo;
- l’applicazione è fuori supporto e non esistono più aggiornamenti;
- l’applicazione non è più in commercio e/o il produttore non esiste più.
Esistono poi una serie di motivazioni più operative, ad esempio:
- nessuno vuole prendersi la responsabilità di aggiornare un’applicazione mission critical;
- non esiste un vero e proprio sistema di rollback;
- il rischio di incorrere in problematiche è superiore al rischio di tenere l’applicazione così com’è.
Questa situazione sempre in ambito ICS/OT e in particolare in ambienti produttivi, medicali, navali, utilities, oil&gas… Ma andando a ben vedere ogni azienda ha degli applicativi che non possono essere aggiornati.
Occorre anche riflettere sul fatto che molto spesso i processi aziendali sono legati ad uno specifico applicativo. L’evoluzione di tale applicativo è spesso più rapido della velocità con la quale è possibile far evolvere i processi aziendali. Un esempio su tutti: l’azienda si basa su uno specifico CRM con alcune personalizzazioni che risultano chiave per i processi aziendali. Le major release successive di tale CRM non garantiscono la piena portabilità delle personalizzazioni, costringendo all’azienda a spendere tempo e risorse per inseguire, di volta in volta, la release seguente.
Appare quindi ovvio che se usiamo il patching come unico sistema per risolvere le vulnerabilità software, avremo sempre un certo insieme di oggetti non gestibili.
Se torniamo ad un approccio risk-based, le cose cambiano.
Se conosciamo il rischio associato a ciascun applicativo (e quindi asset), possiamo confinarlo in una specifica zona di sicurezza protetta da adeguate misure di sicurezza. Se, ad esempio, abbiamo sistemi industriali particolarmente vulnerabili e importanti allo stesso tempo, possiamo confinarli in una zona di sicurezza. Le comunicazioni da e verso tale zona possono essere limitate e controllate per ridurre il rischio di compromissione.
Abbiamo appena descritto il Purdue model (SANS Secure Architecture for Industrial Control Systems) che prevede di creare una zona di contenimento tra il mondo IT e OT.
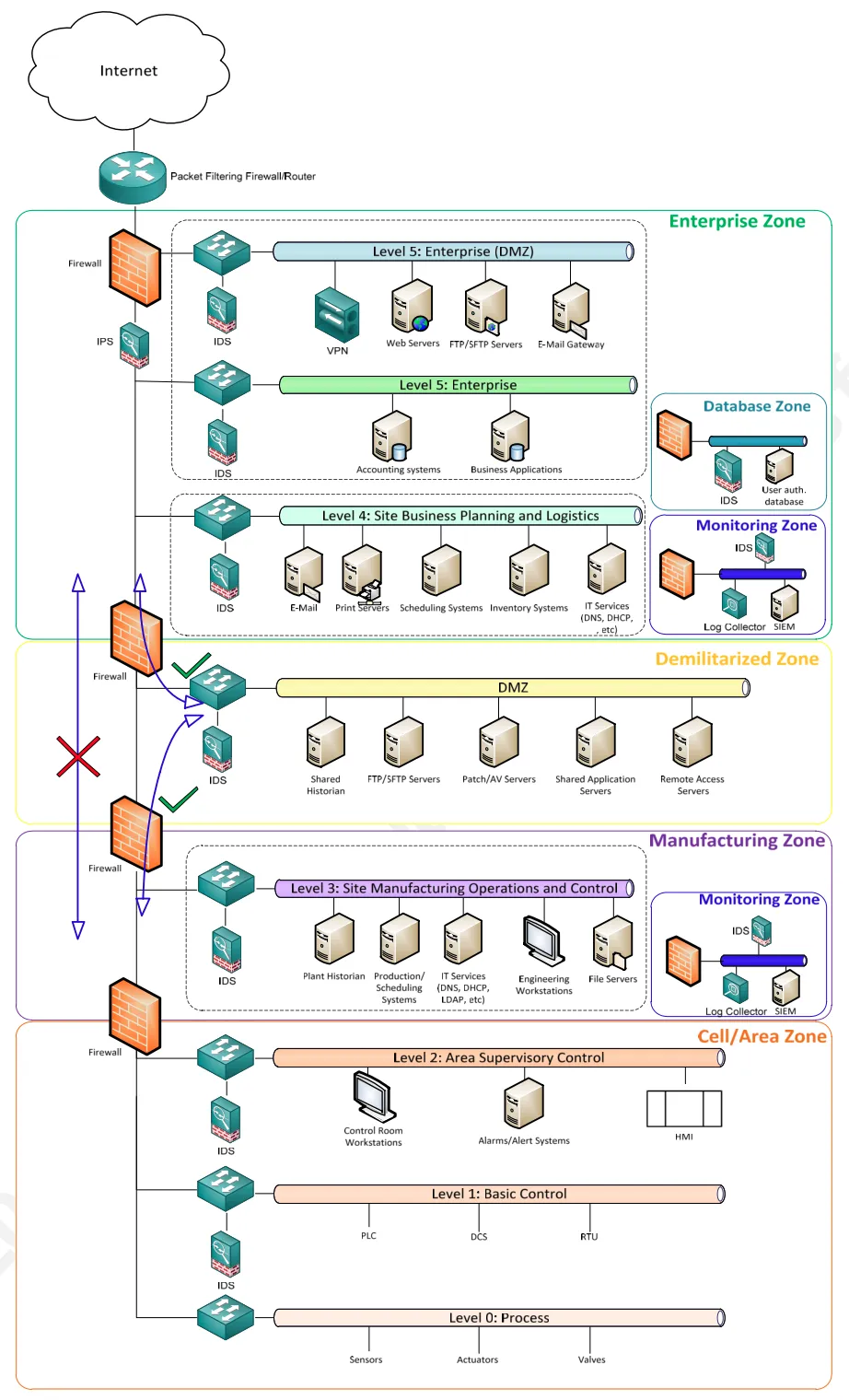
Non è detto che il Purdue Model sia implementabile nella propria azienda, anzi probabilmente non lo è, ma possiamo usare quell’idea per separare gli applicativi critici e non aggiornabili da quelli gestibili. Ottimizzando le misure di sicurezza possiamo creare una barriera sufficientemente robusta per proteggere anche i dispositivi più fragili.
Le misure di sicurezza possono includere:
- Firewall con regole particolarmente stringenti;
- Web Application Firewall
- EDR / XDR;
- analisi comportamentale;
- servizi di monitoraggio attivo;
- NAC;
- Microsegmentazione;
- sonde di rete;
- Honeypot;
- …
Nella pratica il mio consiglio è di partire da un asset inventory ben strutturato. Ciascun asset dovrebbe essere caratterizzato in base al suo impatto sul business aziendale (vedi NIS2) e sui dati personali (GDPR). Ogni asset dovrebbe avere inoltre una finestra di manutenzione definita: questo valore è chiave per capire quanto possiamo operare su un asset senza impattare l’azienda.
Laddove la finestra di manutenzione risulta insufficiente a garantire una corretta manutenzione, dobbiamo mitigare l’eventuale rischio di compromissione agendo sulle misure di sicurezza.
Possiamo quindi definire le necessarie zone di sicurezza protette da misure di sicurezza aggiuntive. Idealmente le misure di sicurezza possono essere rappresentate da un fattore numerico, che può essere usato per calcolare il rischio residuo. In questo modo, per ciascuna zona di sicurezza, si avrà un fattore di mitigazione associabile agli asset contenuti nella zona stessa.
Questo approccio permette di estendere i classici strumenti di vulnerability scanning includendo il contesto, ossia la protezione derivata dalla zona di sicurezza in cui risiedono.
VA Scanner
Il sistema più comune oggi per conoscere quali vulnerabilità software sono presenti in azienda è il Vulnerability Assessment (VA). Nello specifico parliamo di applicazioni di Vulnerability Scanner che scansionano la rete alla ricerca di vulnerabilità conosciute. Le vulnerabilità vengono rilevate grazie alla firma: se un servizio annuncia la sua versione ed essa è vulnerabile, lo scanner riporterà come vulnerabile tale servizio.
Appare chiaro di quanto questi strumenti siano sopravvalutati.
Rischio generico
I Vulnerability Scanner restituiscono un report delle vulnerabilità rilevate, associando un rischio a ciascuna vulnerabilità. Tale fattore di rischio è ovviamente incompleto: manca il contesto.
Tuttavia abbiamo già visto come rapportare il rischio associando le informazioni specifiche dell’asset e delle misure di sicurezza disponibili.
Copertura limitata
L’efficacia dello scanner, ossia la capacità di trovare tutte le vulnerabilità presenti nell’infrastruttura, è legato al database delle firme che lo scanner stesso utilizza. Nessuno scanner può avere una copertura del 100% per due motivi:
- il parco software è particolarmente variegato e ci sono prodotti (come Wordpress) che possono essere estesi da un ecosistema vastissimo di plugin;
- in ogni azienda è quasi sempre presente un applicativo custom.
Se l’utilità di un Vulnerability Scanner è indubbia perché permette di analizzare migliaia di dispositivi in tempi molto ridotti, è anche vero che occorre pianificare approfondimenti su applicativi noti per non essere coperti dallo scanner.
Infine vale la pena menzionare il fatto che molte aziende si rivolgono a diversi fornitori per effettuare i VA, con la speranza di ottenere, nel tempo, una maggiore copertura. Appare ovvio che se le aziende utilizzano tutte lo stesso scanner, il risultato sarà il medesimo. Al massimo potrà differire l’interpretazione.
Vulnerabilità locali
Nella quasi totalità dei casi, i Vulnerability Assessment si limitano alla scansione di rete. In questo modo perdiamo completamente di vista tutte le vulnerabilità locali che, ad esempio, possono essere sfruttate per elevare i privilegi dopo essere riusciti ad ottenere un’utenza locale.
Scanning annuali
Se il Vulnerability Assessment viene effettuato per rilevare le vulnerabilità, dobbiamo considerare il massimo tempo che può intercorrere da quando una vulnerabilità diventa pubblica (e comincia ad essere sfruttata) e quando noi ne veniamo a conoscenza.
Abbiamo visto che lo sfruttamento attivo di una vulnerabilità può avvenire già dopo poche decine di minuti da quanto essa è stata scoperta. Ha quindi poco senso effettuare scanning annuali, semestrali, trimestrali, mensili…
Verifica non rilevazione
I sistemi di vulnerability scanning non sono quindi il sistema per venire a conoscenza delle vulnerabilità, ma sono il sistema che controlla il processo di vulnerability management.
In altre parole se il processo di vulnerability management funziona, il report dello scanner sarà sempre (o quasi) inutile.
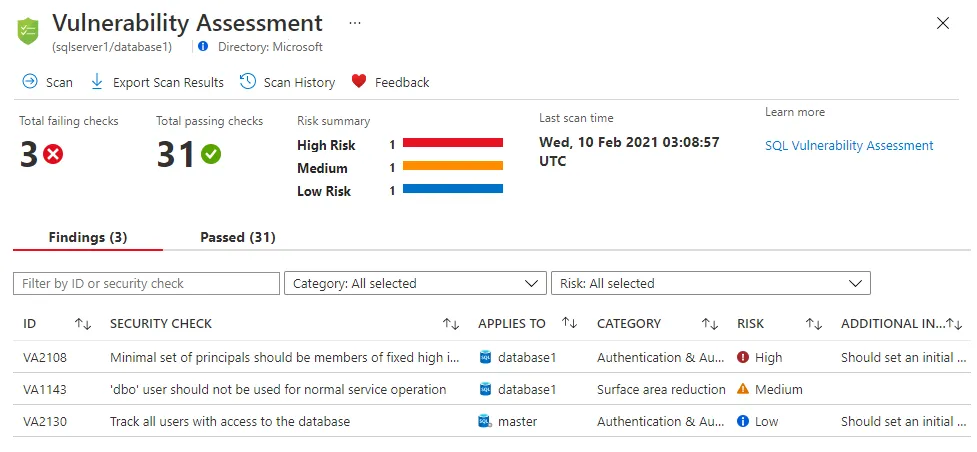
Vulnerability management
Il processo di vulnerability management mette assieme tutte le considerazioni che abbiamo fatto fino ad ora e formalizza le modalità operative. L’apertura del processo si ha quando una nuova vulnerabilità viene rilevata, e questo può avvenire da varie fonti:
- report;
- strumenti automatici;
- persone.
Ciascuna segnalazione verrà analizzata valutata per comprenderne il rischio. Se il rischio inerente, rivalutato quindi in base alle misure di sicurezza già esistenti, supera la soglia di attivazione, sarà necessario attivare il processo di change management per mitigare ulteriormente la vulnerabilità.
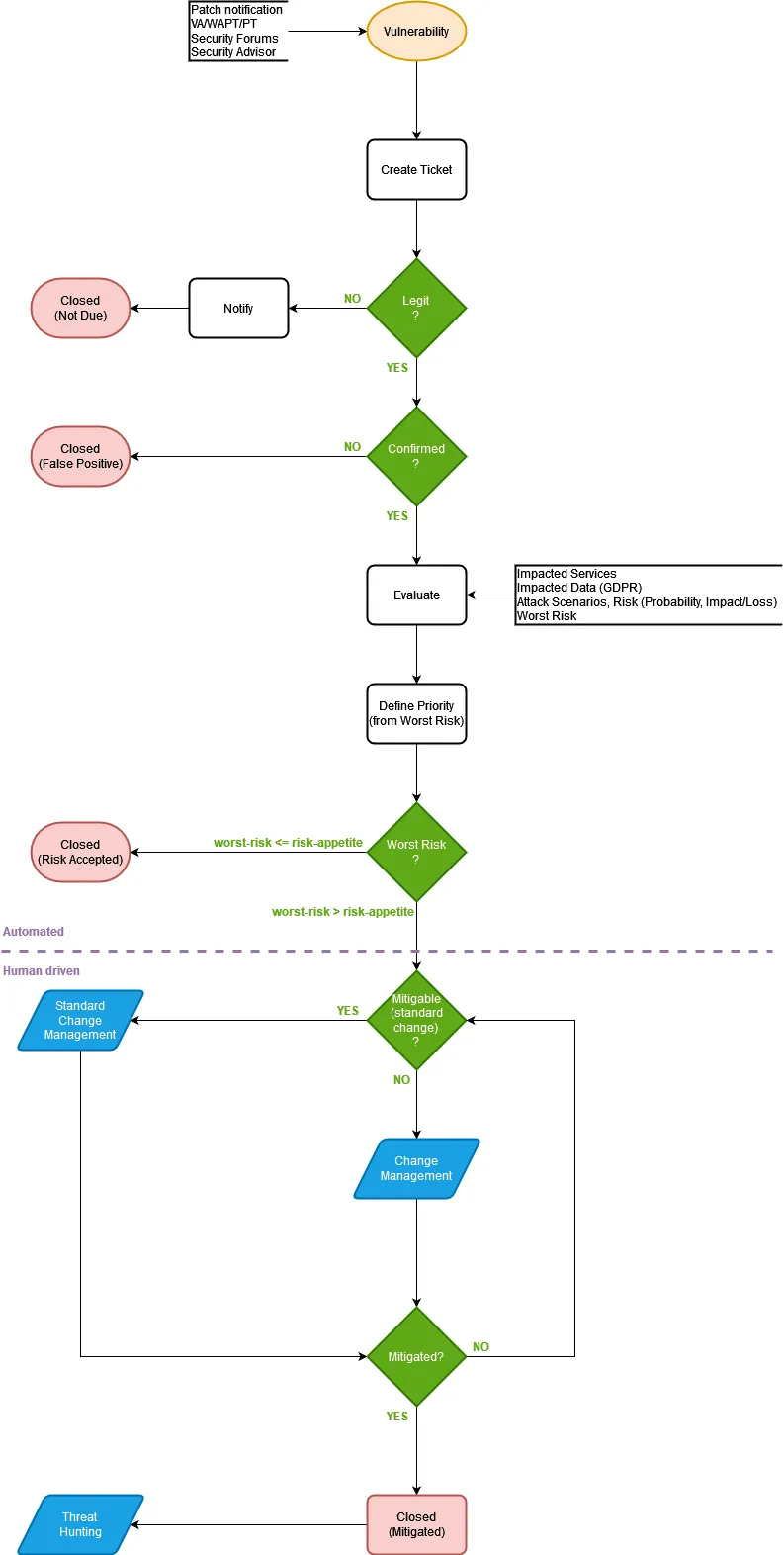
Per riassumere:
- Patch Management: riguarda l’aggiornamento del software alle versioni attualmente supportate. Gli aggiornamenti per risolvere dei bug funzionali rientrano in questo processo.
- Application life cycle management: riguarda l’eliminazione o la migrazione delle applicazioni obsolete giunte a fine vita.
- Vulnerability management: riguarda la riduzione del rischio associato alle vulnerabilità note.
Automation
Abbiamo visto che l’intervallo di tempo che intercorre tra la scoperta di una vulnerabilità tecnica e il suo sfruttamento “in the wild” è molto piccolo. D’altra parte le vulnerabilità tecniche sono continue e gestire gli aggiornamenti che le risolvono richiede un grande sforzo. Abbiamo visto infine come i sistemi più critici siano quelli più complessi da aggiornare, sia per la difficoltà a fermarli, sia per la riluttanza a modificare sistemi critici che funzionano.
Non possiamo oggi pensare di affrontare il processi di vulnerability management senza l’uso di sistemi automatici o parzialmente automatici. L’automazione più elementare, solitamente applicata ai dispositivi degli utenti finali, prevede un aggiornamento settimanale. Workflow più complessi prevedono, previa conferma, di aggiornare sistemi prima su gruppi di test, quindi su gruppi a criticità crescente.
La mia esperienza mi dice che più un processo è aziendalmente definito ed automatico, meno le persone sono restie a metterlo in discussione. In altre parole se un sistema smette di funzionare a causa di una persona che ha manualmente aggiornato il sistema, la responsabilità cadrà sulla persona. Ma se un sistema è stato aggiornato da un processo aziendale automatico, eventuali malfunzionamenti sono accettati e gestiti.
Immutable OS e container
I sistemi cosiddetti “immutable” non prevedono modifiche. In altre parole un sistema immutabile nasce, viene configurato, tipicamente grazie ad un processo automatico, e muore senza che nessuno lo modifichi. I container, in questo aspetto, si comportano allo stesso modo.
Allo stesso modo i sistemi immutabili e i container non vengono aggiornati, ma vengono distrutti, e ricreati a partire da un template base aggiornato.
Questo approccio, usato da Organizzazioni con un approccio DevOps molto spinto, è l’ideale per:
- gestire i cambiamenti di sistema, compresi gli aggiornamenti;
- creare gruppi di test a criticità crescente;
- applicare aggiornamenti su base quotidiana/oraria;
- effettuare rollback alla versione precedente in pochi istanti.
SBOM e vulnerabilità nei template
Chi sviluppa, ma anche chi utilizza software Open Source, dovrebbe tenere sotto controllo le vulnerabilità delle librerie da cui dipende l’applicazione principale. Può sembrare, ed effettivamente è un’impresa titanica. A meno di non strutturare un processo, automatico, che effettua queste verifiche.
Per capirci l’intento è quello di scongiurare altre situazioni come quella vista per Log4Shell.
Un possibile approccio richiede di usare l’utility di CycloneDX per ottenere l’elenco delle librerie utilizzate da uno specifico software in un formato standard (SBOM o Software Bill of Materials). Tale elenco può essere utilizzato da una seconda utility per analizzare eventuali vulnerabilità:
cyclonedx-npm package.json.bak_00.md > sbom.json
bomber scan sbom.json

Il meccanismo è sicuramente perfettibile ma è un primo inizio per strutturare un processo, tenere, per quanto possibile, sotto controllo le applicazioni installate all’interno dell’Organizzazione.
Post patching (Threat Hunting)
Arriviamo al termine di questo lungo post facendo una considerazione sul ciclo di vita delle vulnerabilità:
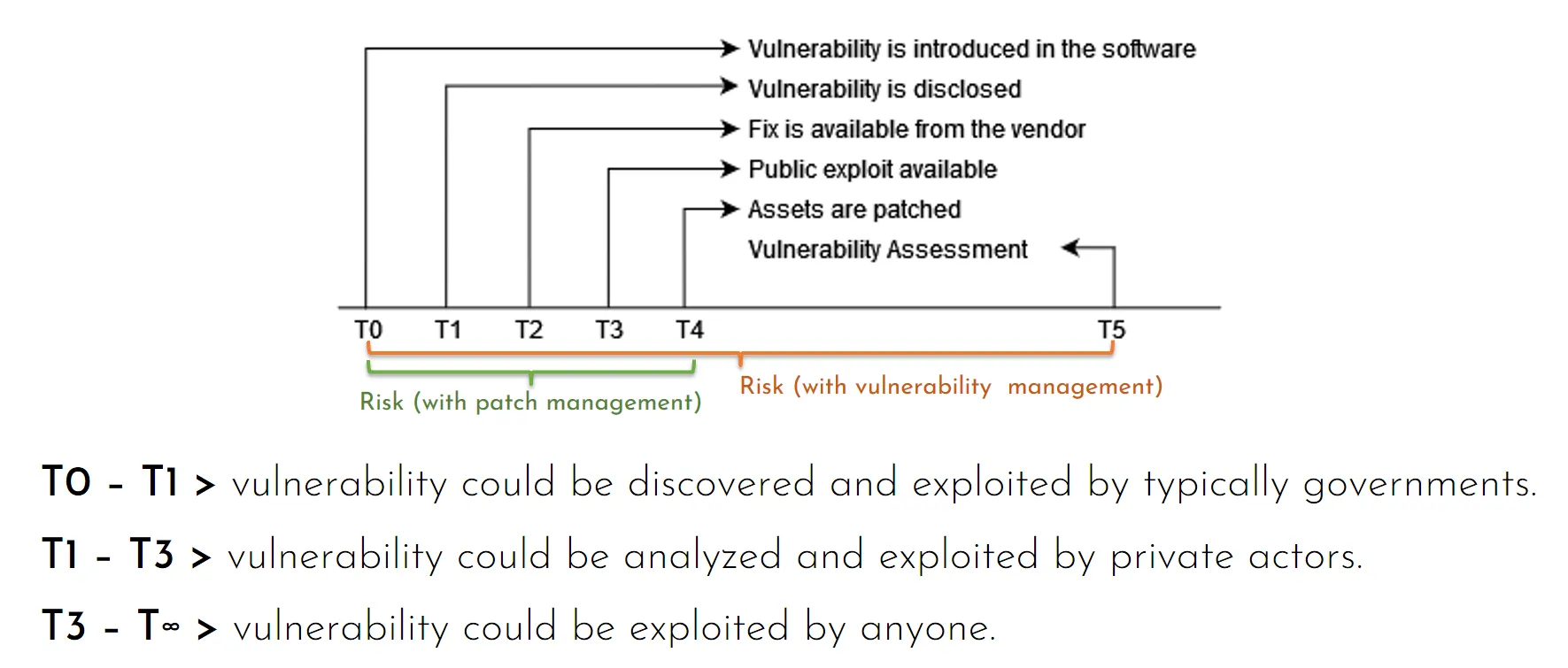
Una volta risolta una vulnerabilità, dobbiamo porci una domanda chiave: è possibile che questa vulnerabilità sia già stata sfruttata? Come possiamo procedere?
La risposta non è semplice, e dipende strettamente dalla vulnerabilità. In alcuni casi alla vulnerabilità sono associati degli indicatori di compromissione (IoC) che ci aiutano a capire se la vulnerabilità è già stata sfruttata, ma in molti casi questi indicatori non sono disponibili.
Idealmente nelle Organizzazioni viene regolarmente effettuata un’attività (Threat Hunting) che ha lo scopo di rilevare minacce silenti già all’interno delle Organizzazioni e, per qualche motivo, non rilevate o bloccate da altri sistemi di sicurezza.
Il nostro processo di vulnerability management potrebbe quindi attivare delle attività di Threat Hunting specifiche per la vulnerabilità che stiamo gestendo. Ad esempio potremmo voler attivare analisi approfondite per vulnerabilità particolarmente critiche, con uno score di EPSS superiore al 70%.